library(powergrid)
sse_pars <- list( # a simple list
n = seq(from = 10, to = 60, by = 5), # sample size
sd = seq(from = 0.1, to = 1, by = 0.1) # standard deviation
)Software packages
Working with statistical software is the daily business of our statisticians. Most software languages allow their users to create their own packages of custom functions to reduce errors in repeated tasks. The software used by SCTO statisticians, primarily R and Stata, are no different in this respect. This page provides an overview of some.
SCTO funded packages
The SCTO Statistics and Methodology platform offers grants to members specifically for the development of such statistical packages, either for the development of completely new software, or the further development of existing software.
powergrid - easy evaluation of functions across a grid of input parameters
![]()
![]()
![]()
The powergrid package is intended to allow users to easily evaluate a function across a grid of input parameters. The utilities in the package are aimed at performing analyses of power and sample size, allowing for easy search of minimum n (or min/max or any other parameter) to achieve a minimal level of power (or a maximum of any value). Also, plotting functions are included that present the dependency of n and power in relation to further parameters.
Example
Define a grid of parameters to evaluate a function across:
Define a function to evaluate the parameters across the grid. The function should take the parameters as input and return a single value (e.g., power, sample size, etc.). For example, we can use the power.t.test function from the stats package to calculate power for a t-test:
PowFun <- function(n, sd){
ptt = power.t.test(n = n/2,
delta = .6,
sd = sd,
sig.level = 0.05)
return(ptt$power)
}Evaluate the function at each grid node:
power <- PowerGrid(pars = sse_pars, fun = PowFun)Display the results:
PowerPlot(power)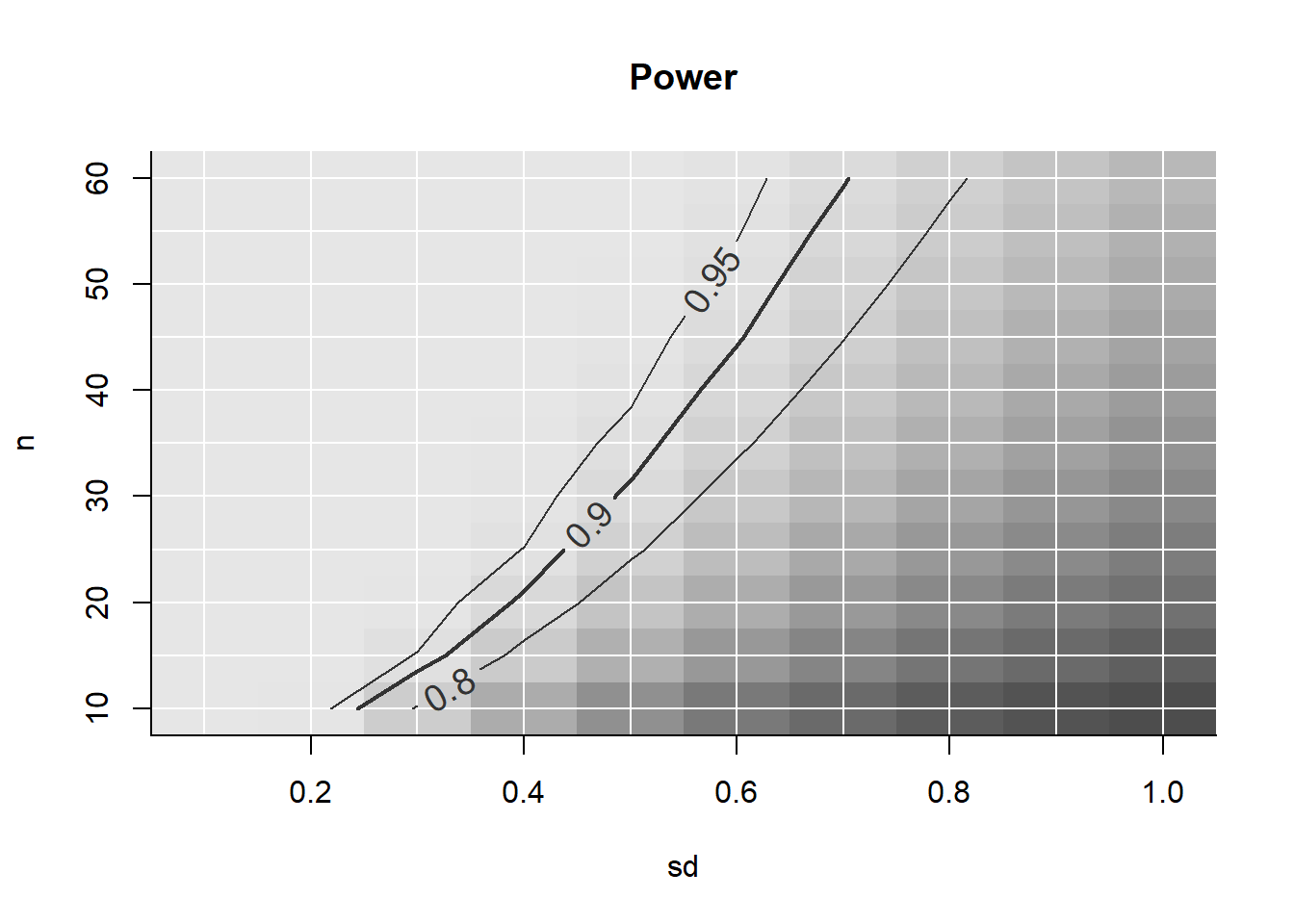
Installation
powergrid can be installed in R via the following methods:
# from CRAN
install.packages("powergrid")
# from CTU Bern's package universe (the development version)
install.packages("powergrid", repos = c('https://ctu-bern.r-universe.dev', 'https://cloud.r-project.org'))
# from github
remotes::install_github("swissclinicaltrialorganisation/powergrid")presize - precision based sample size estimation
![]()
![]()
![]()


presize is an R package for precision based sample size calculation. It provides a large number of methods for estimating the number of samples required to gain a confidence interval of a given width, or the width that might be expected with a given sample size.
Example
Assuming that we want to estimate the confidence interval (CI) around the sensitivity of a test, but we’re not sure of the sensitivity, we can estimate the CI width in a range of scenarios as follows.
Code
library(presize)
# set up a range of scenarios
scenarios <- expand.grid(sens = seq(.5, .95, .1),
prev = seq(.1, .2, .04),
ntot = c(250, 350))
# calculate the CI width at ntot individuals with prev prevalence of event
scenario_data <- prec_sens(sens = scenarios$sens,
prev = scenarios$prev,
ntot = scenarios$ntot,
method = "wilson")
# plot the scenarios with ggplot2
scenario_df <- as.data.frame(scenario_data)
library(ggplot2)
ggplot(scenario_df,
aes(x = sens,
y = conf.width,
# convert colour to factor for distinct colours rather than a continuum
col = as.factor(prev),
group = prev)) +
geom_line() +
labs(x = "Sensitivity", y = "CI width", col = "Prevalence") +
facet_wrap(vars(ntot))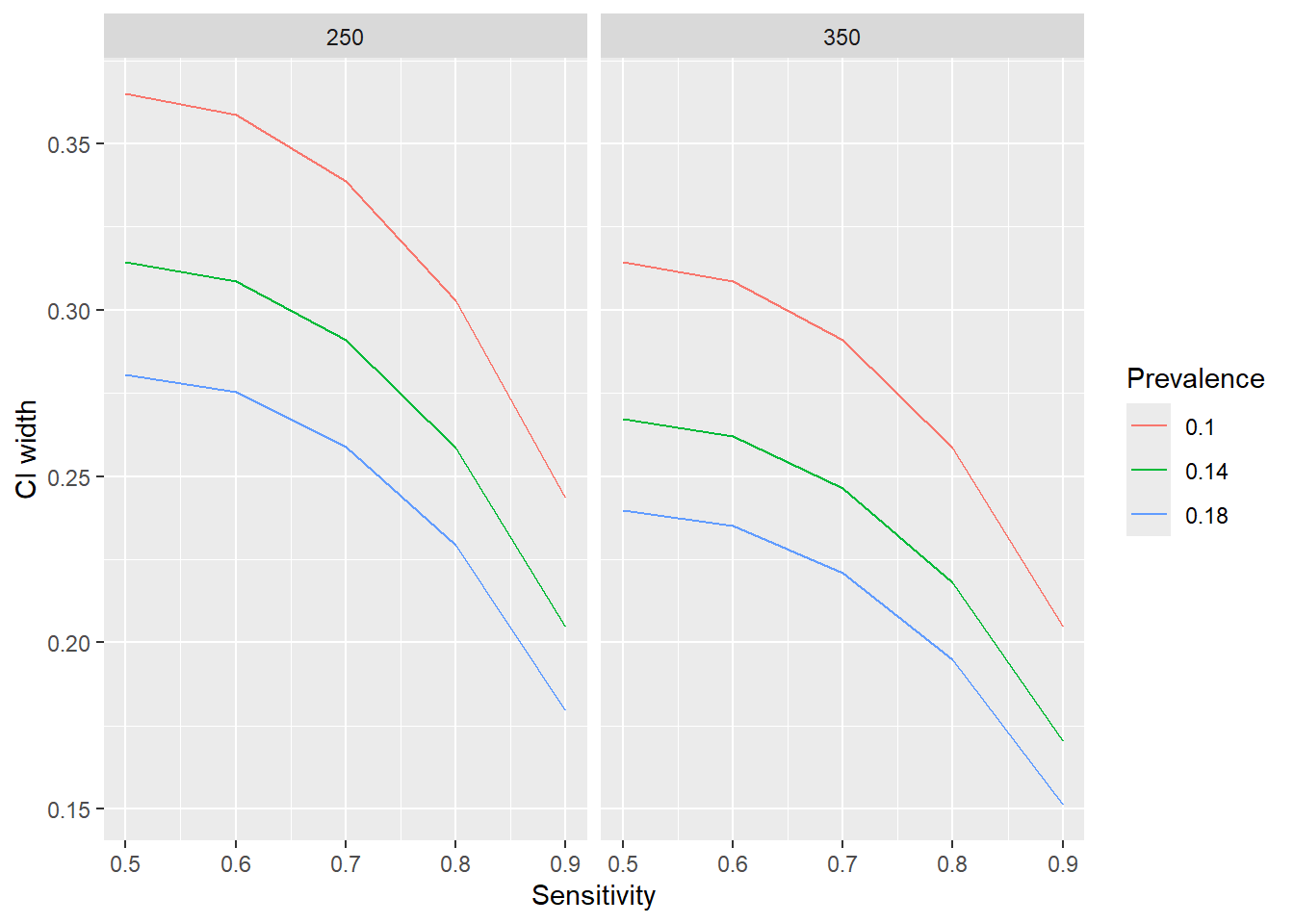
For ease of use, presize also includes a shiny app for point-and-click use, which is also available on the internet.
Installation
presize can be installed in R via the following methods:
# from CRAN (the stable version)
install.packages("presize")
# from CTU Bern's package universe (the development version)
install.packages("presize", repos = "https://ctu-bern.r-universe.dev/")randotools - tools for creating randomisation lists in R
![]()
![]()
![]()
Randomisation lists are at the core of randomized trials, yet existing packages to generate lists lack features. randotools provides a simple API to create stratified, blocked randomisation lists, reports of the randomisation lists, methods to export the generated list to REDCap or secuTrial. It also provides tools for assessing the appropriateness of settings prior to generating a randomisation list (e.g. block sizes and number of strata) and the balance observed in minimization.
Example
The balance that might be expected with a given number of strata and block size can be estimated with the check_plan function:
set.seed(456)
check_plan(50, n_strata = 5, n_sim = 100)
#>
#> Number of simulated trials: 100
#> Number of participants per trial: 50
#> Number of strata: 5
#> Blocksizes: 2, 4
#> Mean imbalance: 1.66 Distribution of imbalance:
#> imbalance n % cum%
#> 0 35 35 35
#> 2 49 49 84
#> 4 14 14 98
#> 6 2 2 100
#>
#> Worst case imbalance from simulations:
#> arm n
#> 1 A 22
#> 2 B 28Randomization lists are generated with randolist
set.seed(123)
r <- randolist(50, arms = c("Trt1", "Trt2"), strata = list(sex = c("Female", "Male")))A short report on randomisation lists can be generated via a summary method:
summary(r)Installation
randotools can be installed in R via the following methods:
# from CTU Bern's package universe (the development version)
install.packages("randotools", repos = c('https://ctu-bern.r-universe.dev', 'https://cloud.r-project.org'))
# from github
remotes::install_github("CTU-Bern/randotools")redcaptools - a package for working with REDCap data in R
![]()
![]()
![]()
REDCap is a popular database for clinical research, used by many of the CTUs in Switzerland. One aggravation with REDCap data exports is that the data is in one file which can contain a lot of empty cells when more complicated database designs are used. redcaptools has tools to automatically pull the database apart into forms for easier use. Similar to secuTrialR, it also labels variables, and prepares date and factor variables. The function is primarily for interacting with REDCap via the Application Programming Interface (API), allowing easy scripted exports.
Example
By supplying the API token generated by REDCap, together with the APIs URL, the redcap_export_byform function can be used to export all data from the database by form. Each form is returned as an element of a list.
library(redcaptools)
token <- "some-long-string-provided-by-redcap"
url <- "https://link.to.redcap/api/"
dat <- redcap_export_byform(token, url)The ‘normal’ format can be exported via the redcap_export_tbl function:
record_data <- redcap_export_tbl(token, url, "record")
meta <- redcap_export_tbl(token, url, "metadata")This function can also be used to export various other API endpoints (e.g. various types of metadata etc, specific forms).
The data can then be formatted by using the metadata and the rc_prep function
prepped <- rc_prep(dat, meta)Installation
redcaptools can be installed in R via the following methods:
# from CTU Bern's package universe (the development version)
install.packages("redcaptools", repos = c('https://ctu-bern.r-universe.dev', 'https://cloud.r-project.org'))
# from github
remotes::install_github("CTU-Bern/redcaptools")selcorr - post-selection inference for generalized linear models
![]()

When variable selection is performed in statistical models, the subsequent confidence intervals and p-values are overly optimistic. selcorr calculates (unconditional) post-selection confidence intervals and p-values for the coefficients of (generalized) linear models.
Example
library(selcorr)
## linear regression:
selcorr(lm(Fertility ~ ., swiss)) Estimate CI lower CI upper p
(Intercept) 62.1013116 42.71786664 81.48475647 8.491981e-08
Agriculture -0.1546175 -0.29223032 -0.01700466 1.982091e-02
Education -0.9802638 -1.39242064 -0.56810702 1.824604e-05
Catholic 0.1246664 0.04632685 0.20300594 1.658185e-03
Infant.Mortality 1.0784422 0.30780496 1.84907938 4.254657e-03## logistic regression:
swiss.lr = within(swiss, Fertility <- (Fertility > 70))
selcorr(glm(Fertility ~ ., binomial, swiss.lr))A parallel bootstrapping approach is also available.
Code
library(future.apply)
plan(multisession)
boot.repl = future_replicate(8, selcorr(lm(Fertility ~ ., swiss), boot.repl = 1000,
quiet = TRUE)$boot.repl, simplify = FALSE)
plan(sequential)
selcorr(lm(Fertility ~ ., swiss), boot.repl = do.call("rbind", boot.repl))Installation
selcorr can be installed in R from CRAN:
# from CRAN (the stable version)
install.packages("selcorr")sts_graph_landmark - landmark analysis graphs
![]()
![]()
sts_graph_landmark is a Stata program to create landmark analysis Kaplan-Meier curves, complete with risk table.
Example
Using sts_graph_landmark is consistent with the other sts_* programs in Stata. The dataset should be stset and then sts_graph_landmark can be called specifying the landmark time in at.
Code
# load example dataset (note: this example is nonsensical and only for graphing purposes)
webuse stan3, clear
# set data as survival data
stset t1, failure(died) id(id)
# label treatment arms
label define posttran_l 0 "prior transplantation" 1 "after transplantation"
label value posttran posttran_l
# create landmark plot and table
sts_graph_landmark, at(200) by(posttran) risktable
Installation
It can be installed from github:
net install github, from("https://haghish.github.io/github/")
github install CTU-Bern/sts_graph_landmarksecuTrialR - import secuTrial datasets to R
![]()
![]()
![]()


secuTrial datasets consist of a lot of files and it can be difficult to get to grips with them. secuTrialR tries to reduce the burden by providing a method to import and format (e.g. adding labels to variables) and explore data.
Example
Data can be read into R using read_secuTrial. The visit_structure function gives an idea of which forms are required at which visit. plot_recruitment is for plotting trial recruitment.
Code
library(secuTrialR)
# prepare path to example export
export_location <- system.file("extdata", "sT_exports", "snames",
"s_export_CSV-xls_CTU05_short_miss_en_utf8.zip",
package = "secuTrialR")
# read all export data
sT_export <- read_secuTrial(data_dir = export_location)
plot(visit_structure(sT_export))
plot_recruitment(sT_export)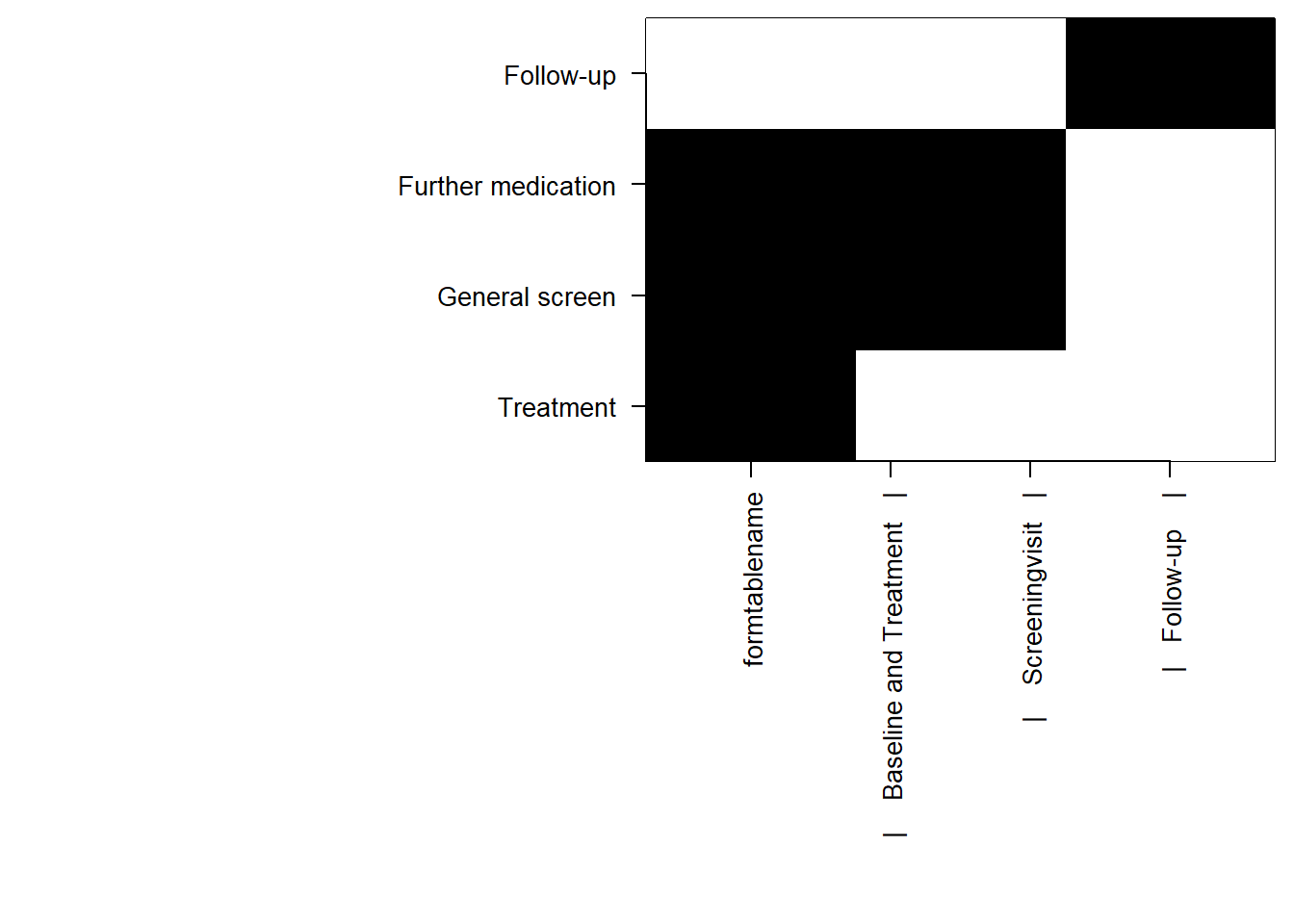
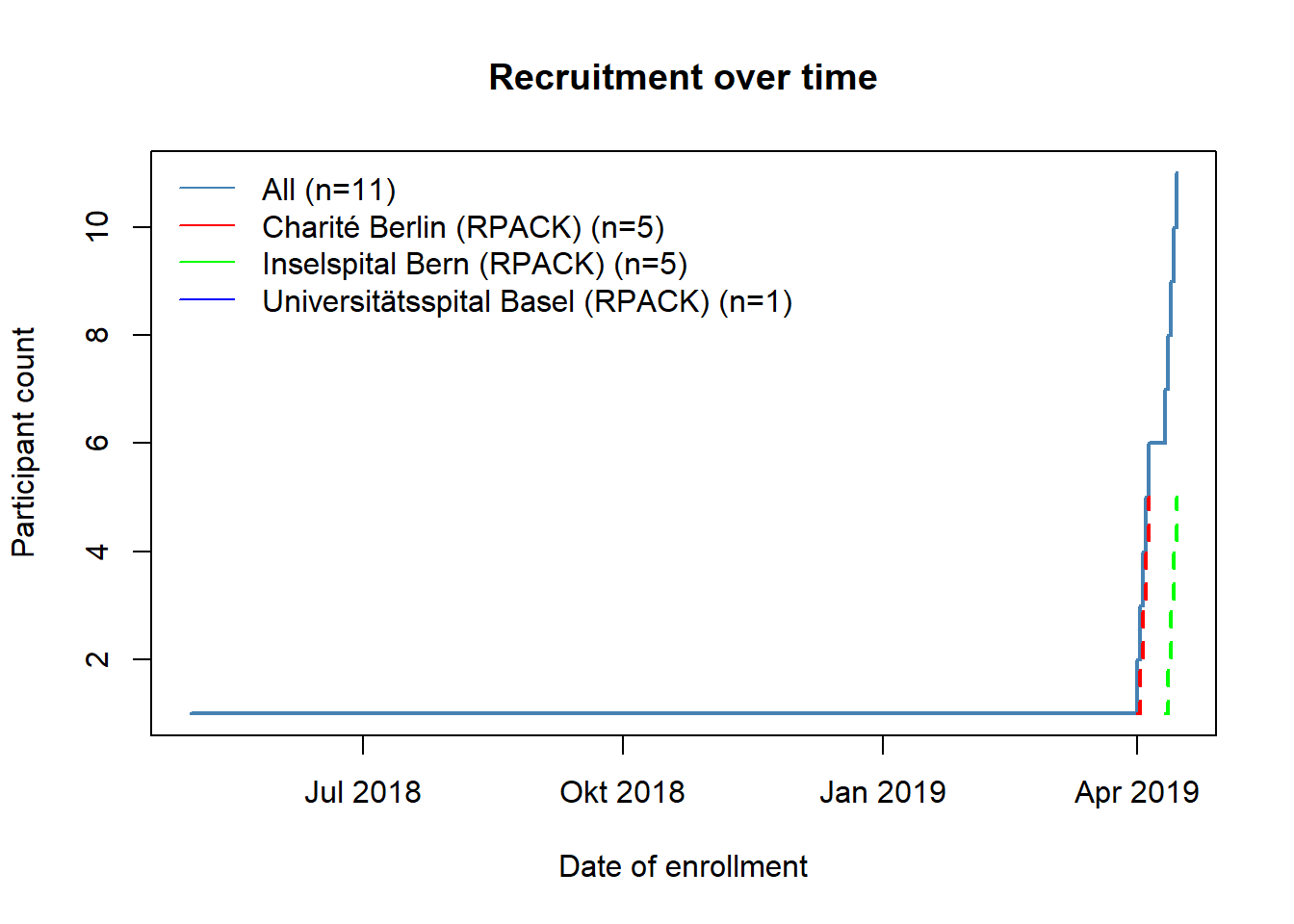
secuTrialR was developed by the data management platform with substantial input from members of the statistics and methodology platform.
Installation
secuTrialR can be installed in R via the following methods:
# from CRAN (the stable version)
install.packages("secuTrialR")
# from CTU Bern's package universe (the development version)
install.packages("secuTrialR", repos = c('https://ctu-bern.r-universe.dev', 'https://cloud.r-project.org'))survSAKK - Kaplan-Meier curves in R
![]()
![]()
![]()
survSAKK provides tools to ease some of the pain-points in the creation of Kaplan-Meier curves in R.
Example
# Load required library
library(survSAKK)
library(survival)
# Fit survival object
fit <- survfit(Surv(lung$time/365.25*12, status) ~ sex, data = lung)
# Generate surival plot
surv.plot(fit = fit,
time.unit = "month",
legend.name = c("Male", "Female"))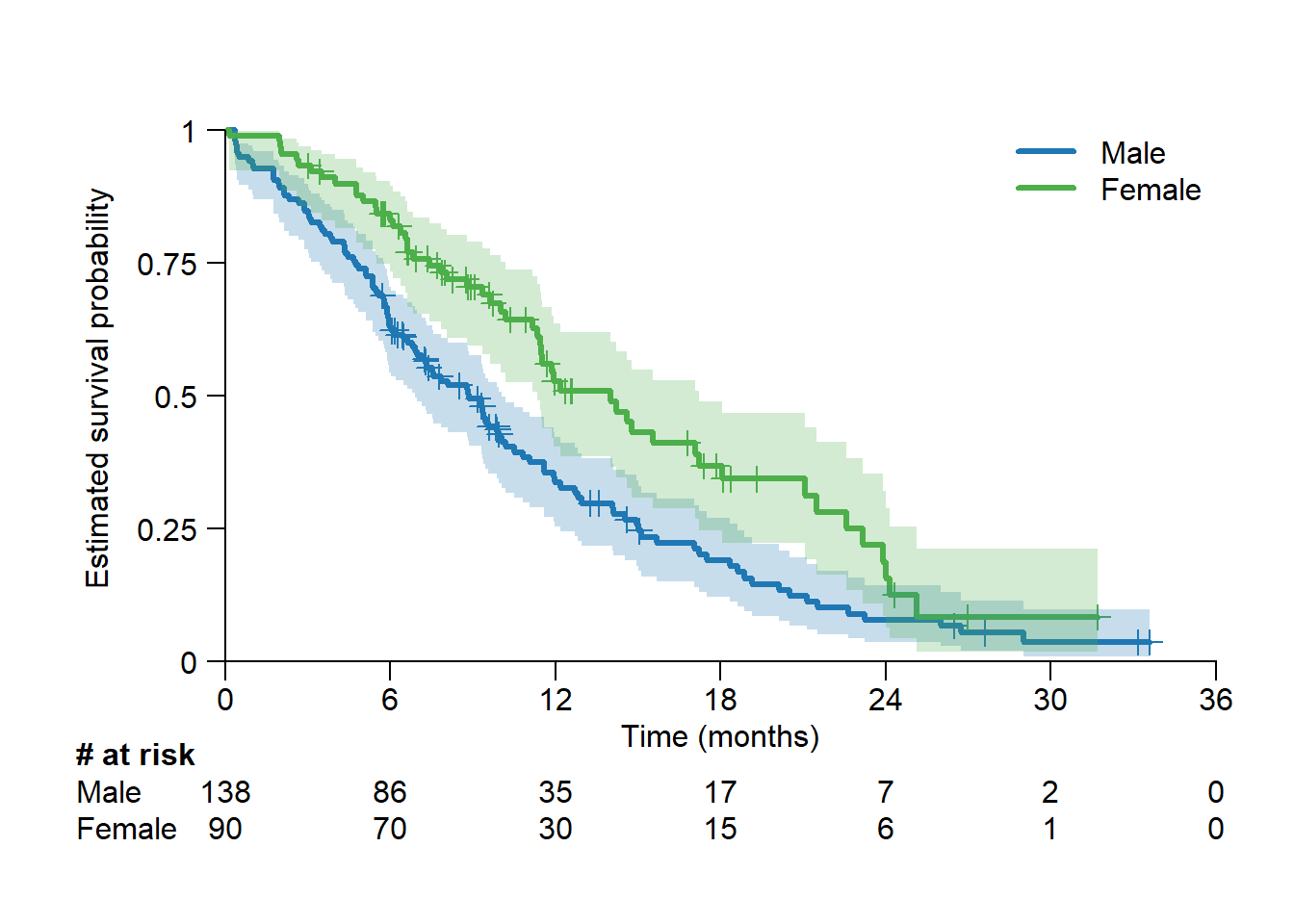
Installation
survSAKK can be installed in R via the following methods:
# from CRAN (the stable version)
install.packages("survSAKK")
# from CTU Bern's package universe (the development version)
install.packages("survSAKK", repos = c('https://ctu-bern.r-universe.dev', 'https://cloud.r-project.org'))Other software developed by CTUs
CTU’s sometimes also develop software without explicit funding from the SCTO platform. Those packages are listed below.
accrualPlot - simple creation of accrual plots
![]()
![]()
![]()

accrualPlot is an R package for summarizing trial recruitment data. With relatively little code, it is possible to create various plots and tables useful for recruitment reports, as well as predict the end of recruitment based on the recruitment to date.
Example
accrualPlot includes a simulated dataset of participants recruited into a trial in one of three sites. The accrual_create_df function is used to define the properties of the sites (e.g. start dates if that differs from the first participants recruitment date). The plot and summary functions can then be used to plot or tabulate the data. The data can be plot using either base graphics or ggplot2.
Code
library(accrualPlot)
data(accrualdemo)
df <- accrual_create_df(accrualdemo$date, by = accrualdemo$site)
# cumulative recruitment
plot(df, which = "cum", engine = "ggplot2")
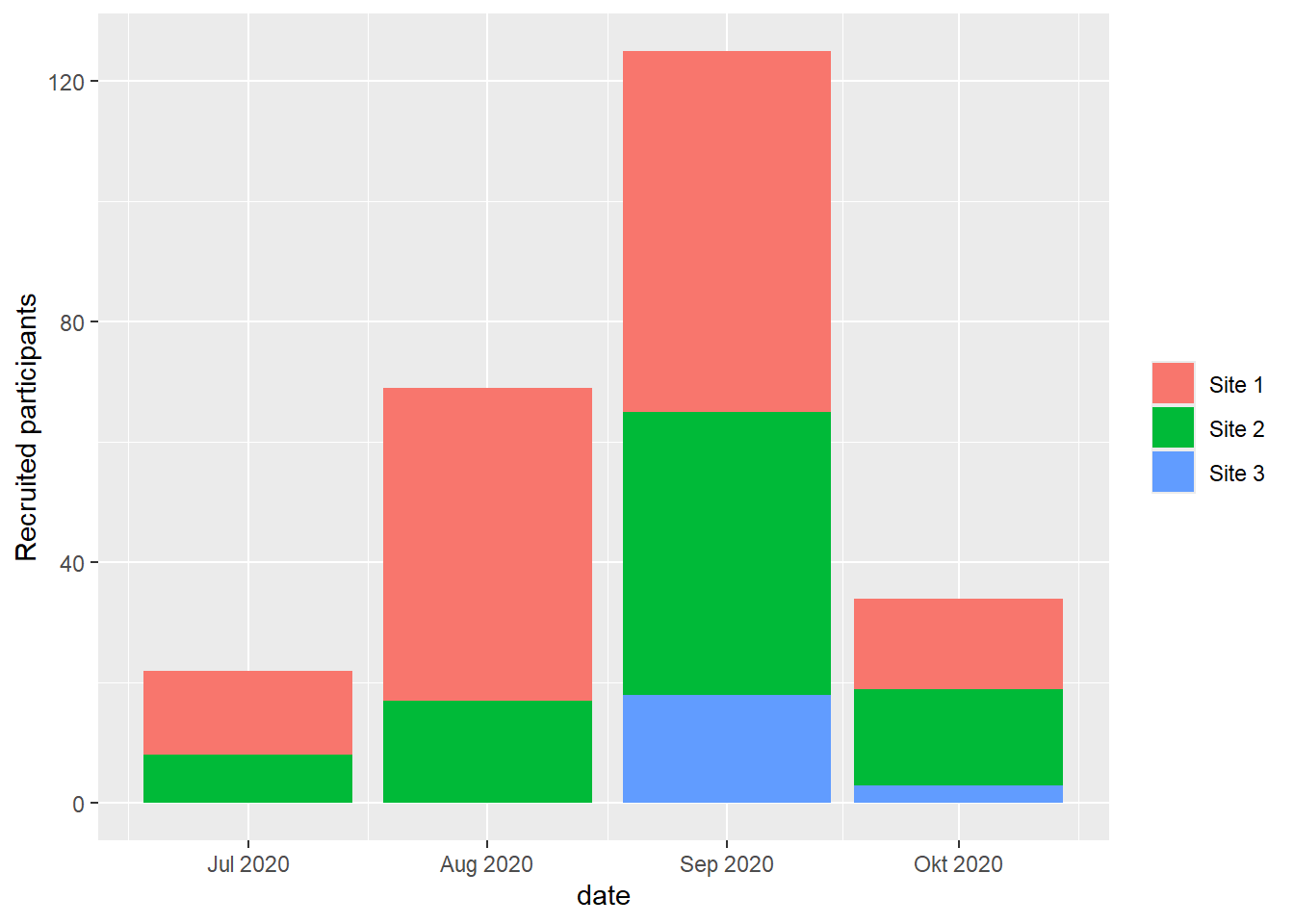
# absolute recruitment (daily/weekly/monthly)
plot(df, which = "abs", engine = "ggplot2")
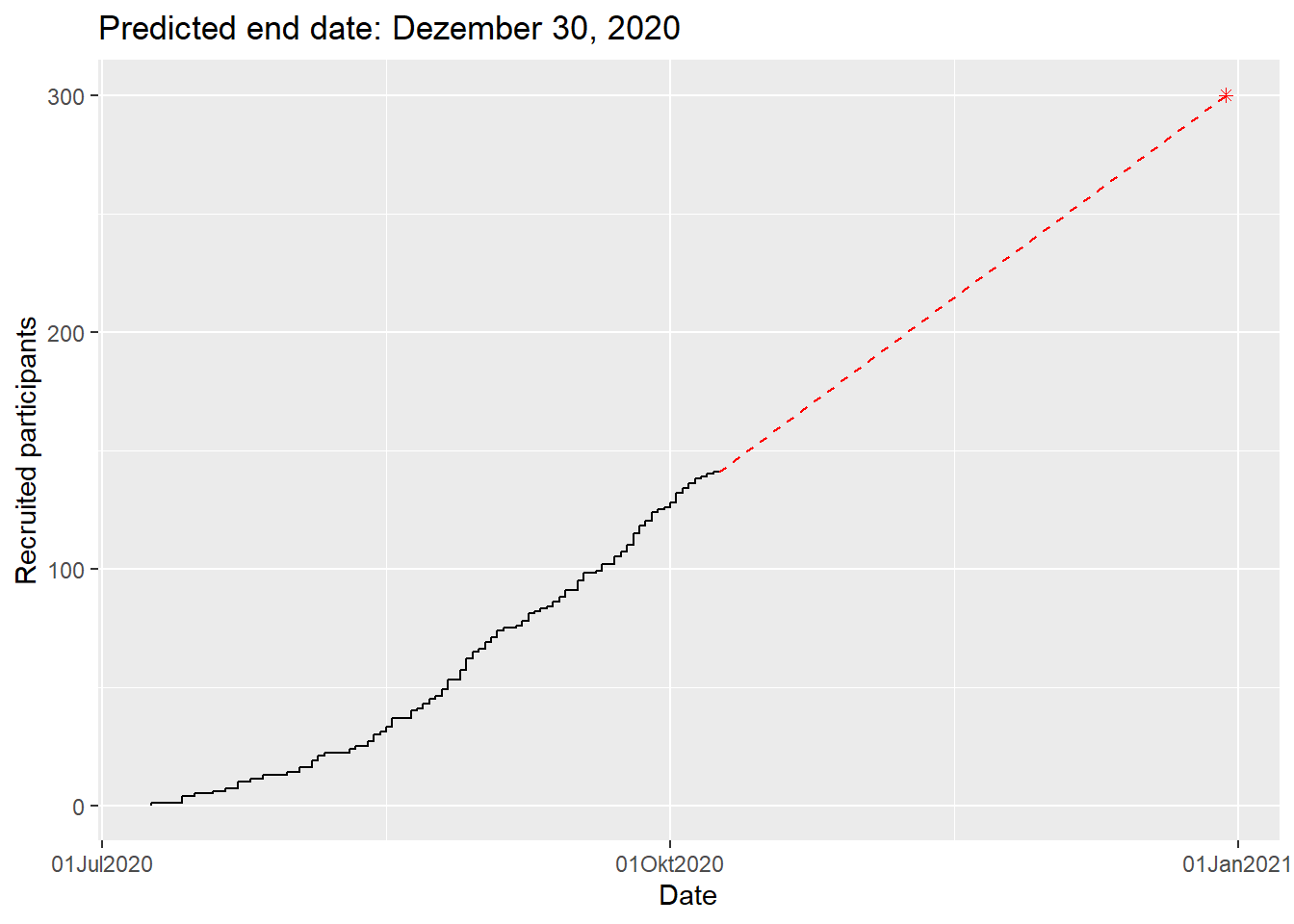
# predict end date
plot(df, which = "pred", target = 300, engine = "ggplot2")Warning in geom_point(aes(x = edate, y = targetm), col = col.pred, pch = pch.pred): All aesthetics have length 1, but the data has 67 rows.
ℹ Please consider using `annotate()` or provide this layer with data containing
a single row.Code
# summary table
library(gt)
gt(summary(df)) %>%
tab_options(column_labels.hidden = TRUE)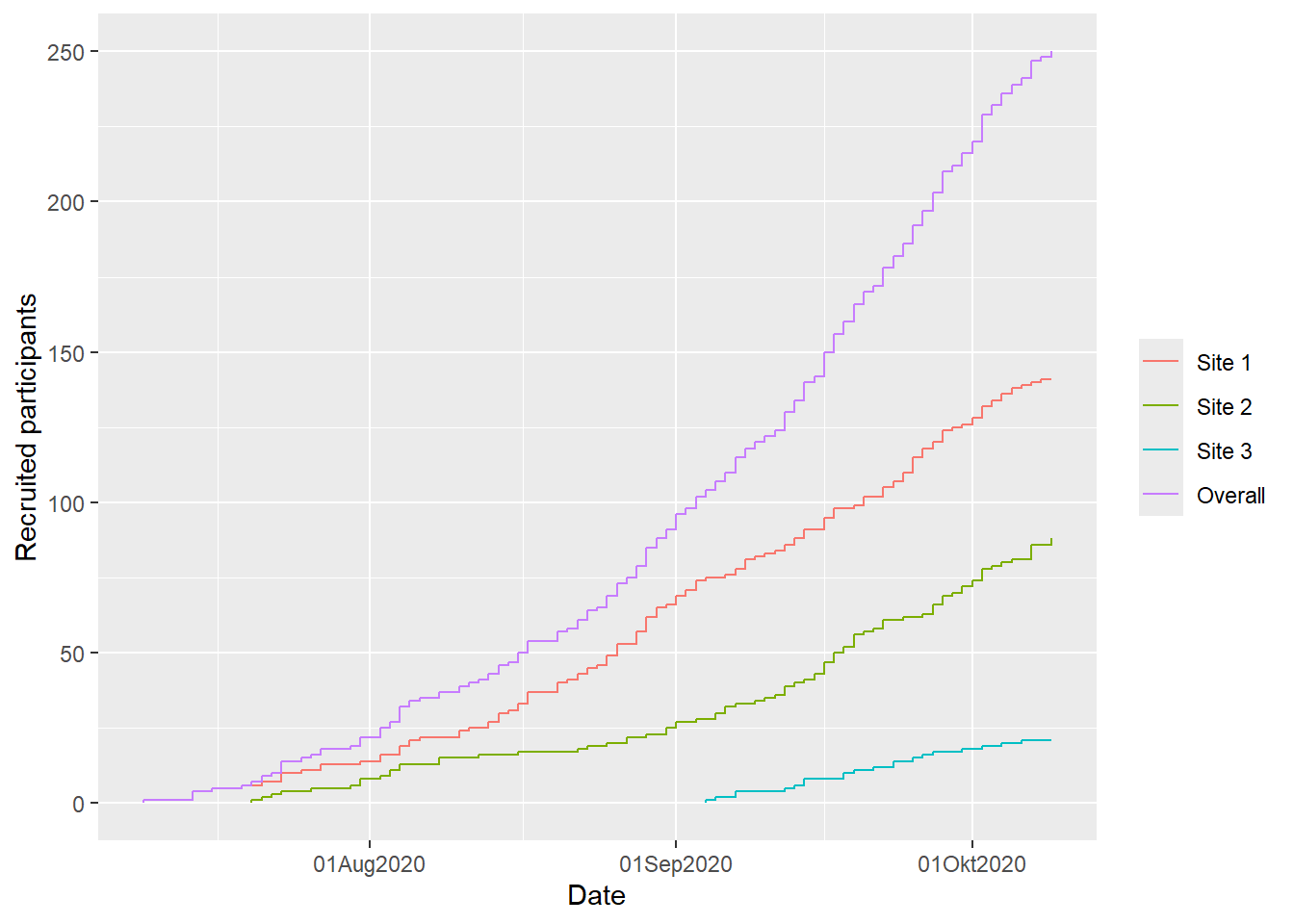
| Center | First participant in | Months accruing | Participants accrued | Accrual rate (per month) |
| Site 1 | 09Jul2020 | 3 | 141 | 45.98 |
| Site 2 | 20Jul2020 | 3 | 88 | 32.59 |
| Site 3 | 04Sep2020 | 1 | 21 | 18.00 |
| Overall | 09Jul2020 | 3 | 250 | 81.52 |
Installation
accrualPlot can be installed in R via the following methods:
# from CRAN (the stable version)
install.packages("accrualPlot")
# from CTU Bern's package universe (the development version)
install.packages("accrualPlot",
repos = c('https://ctu-bern.r-universe.dev', 'https://cloud.r-project.org'))btable - create baseline tables in Stata
![]()
![]()
Creating baseline tables is a repetitive task. Each paper needs one. btable provides a powerful approach to creating them. See the making baseline tables article for an example. More information on btable can be found here.
Installation
btable can be installed in Stata via the following method:
net install github, from("https://haghish.github.io/github/")
github install CTU-Bern/btablebtabler - format tables for LaTeX reports
![]()
![]()
![]()
btabler adds additional functionality to the xtable package such as merging column headers for use in tables for LaTeX. It was originally developed as an easy way to put tables generated by `btable` into LaTeX reports, hence the similarity in names.
Example
library(btabler)
df <- data.frame(name = c("", "", "Row 1", "Row2"),
out_t = c("Total", "mean (sd)", "t1", "t1"),
out_1 = c("Group 1", "mean (sd)", "g11", "g12"),
out_2 = c("Group 2", "mean (sd)", "g21", "g22"))
btable(df, nhead = 2, nfoot = 0, caption = "Table1")Which will look like this in after LaTeX has created your PDF:

Installation
btabler can be installed in R via the following method:
# from CTU Bern's package universe (the development version)
install.packages("btabler",
repos = c('https://ctu-bern.r-universe.dev', 'https://cloud.r-project.org'))forplot - easy forest plots
![]()
![]()
![]()
forplot provides a simple, yet flexible, approach to creating forest plots in R.
Example
forplot and its main function fplot needs a data frame with specific column names.
- vlabel: a chr column with the variable labels.
- nx: any number of chr or num columns numbered sequentially (i.e. n1, n2, n3, …). Could contain the number of observations and/or summary per group.
- beta, beta_lci, beta_uci: three num columns with point estimates and confidence interval to be plotted as forest.
- beta_format: optional chr column with formatted text to be printed along forest, generated from betas if not given.
- px: any number of chr or num columns numbered sequentially (i.e. p1, p2, p3, …). Could contain p-values.
The order of the columns is kept for the plot.
library(forplot)Warning: Paket 'forplot' wurde unter R Version 4.5.3 erstelltdata(forplotdata)
fplot(dat=forplotdata,
# widths and heights
lwidths = c(0.05,0.5,0.2,0.8,0.2,0.8,1.2,1.2,0.5,0.05),
lheights = c(0.14,1,0.08),
# header
header = c("","Group1\nN","Group0\nmean (sd)","Group2\nN","Group2\nmean (sd)",
"Mean difference\n95% CI","","P-value"),
# xlimits
xlim = c(-1, .5)
)
Installation
forplot can be installed in R via the following methods:
# from CTU Bern's package universe (the development version)
install.packages("forplot",
repos = c('https://ctu-bern.r-universe.dev', 'https://cloud.r-project.org'))
# from github
remotes::install_github("CTU-Bern/forplot")HSAr - create reproducible hospital service areas in R
![]()
![]()
![]()
![]()
Hospital service areas can be useful for hospital planning, but their main use is in small area research. They are traditionally made largely by hand, by assigning each location to the hospital where most residents go and then iteratively moving locations until two main criteria are fulfilled - a HSA should not have detached islands, and at least 50% of it’s hospitalizations should stay there. The iterative steps are largely manual subjective work. As such the reproducibility of HSA creation is poor.
HSAr provides an automated algorithm for creating HSAs by starting at the hospital and building the HSA around it until all regions in the provided shapefile are assigned to a HSA.
HSAr was developed as part of national research programme 74, smarter health care.
Note: HSAr requires R packages that are no longer on CRAN (or if they are, they have greatly reduced functionality). HSAr would require a full rewrite to make it functional with current packages.
Example
Installation
HSAr can be installed in R via the following method:
# from CTU Bern's package universe (the development version)
install.packages("HSAr", repos = "https://ctu-bern.r-universe.dev/")kpitools - tools to assist with risk based management KPIs
![]()
![]()
![]()
It is not enough to simply run a trial. ICH GCP E5 also requires risk based monitoring to be performed. kpitools provides a set of summary functions and a standardized format for presenting the key performance indicators (KPIs) that are typically defined for risk based monitoring strategies.
Example
It could be that we believe that time of day might be an indicator of data fabrication because it’s not possible that participants are randomised at certain times of the day. The fab_tod function can help depict that..
library(kpitools)
set.seed(12345)
dat <- data.frame(
x = lubridate::ymd_h("2020-05-01 13") + 60^2*rnorm(40, 0, 3),
mean = rnorm(40, 56, 20),
by = sample(1:4, 40, prob = c(.2,.25,.4,.4), replace = TRUE)
)
dat %>% kpi("mean", kpi_fn_mean, by = "by") %>% plot
dat %>% fab_tod("x")Installation
kpitools can be installed in R via the following method:
# from CTU Bern's package universe (the development version)
install.packages("kpitools",
repos = c('https://ctu-bern.r-universe.dev', 'https://cloud.r-project.org'))stata_secutrial - some Stata code to do data import and preparation of secuTrial datasets
![]()
![]()
Similar to secuTrialR above, stata_secutrial provides Stata code to read and prepare secuTrial exports in Stata. It labels variables, formats date variables, adds labels to categorical variables etc, saving each form as a dta file for your further use.
Example
Assuming certain folders and globals have been prepared in advance (see GitHub for further information), using stata_secutrial may be as simple as entering
do SecuTrial_zip_data_importinto Stata and then navigating to your download when prompted.
Installation
As stata_secutrial is just code rather than a package, you can copy the files from GitHub and use them in your project. Towards the top of the GitHub page is a green code button. Click that and choose download ZIP. You can then unzip the files to your working directory.
SwissASR - simplified annual safety reports with R
![]()
![]()
![]()
Ethics and regulators often require annual safety reports. SwissASR provides a relatively easy way to produce annual safety reports according to the current template available on the SwissMedic(?) website. The function returns a word file with the safety data completed based on the data provided to it. Minimal additional details should then be added by the study team or principal investigator.
Note: swissethics recently changed the Annual Safety Report to the Annual Safety and General Progress Trial Report, which has a wider scope, which is not possible to automate. SwissASR might still be useful for generating some parts of the report, but there are large parts of the report that cannot be automated. There are therefore currently no plans to update the package to the new template.
Example
Installation
SwissASR can be installed in R via the following method:
# from CTU Bern's package universe (the development version)
install.packages("SwissASR",
repos = c('https://ctu-bern.r-universe.dev', 'https://cloud.r-project.org'))